Felipe Maggi.
Lenguaje de programación: Python.
Siguiendo con la serie de artículos dedicados a la Ciencia de Datos, en la cual ya hemos publicado el capítulo 1 (Data Science I: población, muestra, experimentos y tipos de variables), vamos a tratar ahora la estadística descriptiva unidimensional.
De nuevo nos guiaremos, en cuanto a estructura, por lo expuesto en material de Máster de Big Data y Data Science de la Universidad de Barcelona, cuya autora es Dolores Lorente porque, desde nuestro punto de vista, fasea la materia de forma adecuada.
Los conceptos estadísticos son de dominio general, pero cuando tengamos que recurrir a una forma concreta de plantear las cosas, haremos uso, mayoritariamente, de las definiciones expuestas en el libro Estadística general: lo esencial, de Johnson & Kuby.
También conocida como análisis descriptivo de datos de una sola variable, la estadística descriptiva unidimensional es la rama de la estadística que «se centra en el análisis de una única característica o cualidad del individuo» (Lorente), entre otras cosas, la estadística unidimensional estudia:
- las distribuciones de frecuencias,
- las medidas de tendencia central,
- las medidas de dispersión,
- y la representación gráfica de las variables, tanto cualitativas como cuantitativas.
Distribuciones de frecuencias
Una distribución de frecuencias es una lista en forma de tabla que enlaza los valores que adopta una variable, con el número de veces que aparecen dichos valores en el conjunto de datos analizado.
Para trabajar con ejemplos, vamos a rescatar el conjunto de datos relativos a las notas obtenidas en los exámenes de matemáticas por los estudiantes de segundo de bachillerato del instituto Luis Vives de Valencia, en el año académico 2024-2025, que utilizamos en el primer artículo de esta serie.
IMPORTANTE: No son las notas de verdad, si no un conjunto de datos generados con fines de ejemplo.
import pandas as pd
import numpy as np
import random
import string
import seaborn as sns
import matplotlib.pyplot as plt
# --- CONFIGURACIÓN INICIAL ---
np.random.seed(42)
random.seed(42)
def generar_id_estudiante(n):
ids = []
for _ in range(n):
id_estudiante = ''.join(random.choices(
string.ascii_uppercase + string.digits, k=8))
ids.append(id_estudiante)
return ids
# --- PARÁMETROS ---
num_estudiantes_por_grupo = 40
total_estudiantes = num_estudiantes_por_grupo * 4
num_notas = 10
ids = generar_id_estudiante(total_estudiantes)
asignatura = 'Matemáticas'
temas = [f'Tema {i+1}' for i in range(num_notas)] # Tema 1 al 10
fecha_inicio = pd.Timestamp('2024-09-01')
grupos = ['A', 'B', 'C', 'D']
# --- FUNCIÓN para generar correlación entre notas y tiempo de estudio ---
def generar_tiempo_estudio(notas, media=270, sd_total=60, correlacion=0.75):
"""
Genera tiempos de estudio correlacionados con las notas.
"""
# 1. Calcular desviación estándar de las notas actuales
sd_notas = np.std(notas)
if sd_notas == 0: sd_notas = 1 # Evitar división por cero si todas las
# notas son iguales
# 2. Calcular la pendiente (m) necesaria
# Fórmula de regresión: m = r * (Sy / Sx)
pendiente = correlacion * (sd_total / sd_notas)
# 3. Calcular el ruido residual necesario
# Para mantener la SD total deseada, el ruido se reduce si la
# correlación es alta
sd_ruido = sd_total * np.sqrt(1 - correlacion**2)
# 4. Generar ruido y calcular tiempo
ruido = np.random.normal(0, sd_ruido, len(notas))
tiempo_estudio = media + pendiente * (notas - np.mean(notas)) + ruido
return tiempo_estudio.clip(60, 480).astype(int)
# --- GENERACIÓN DE DATOS ---
data = {
'id_estudiante': [], 'asignatura': [], 'tema': [], 'fecha': [],
'nota': [], 'calificacion': [], 'estatura': [], 'sexo': [],
'tiempo_estudio': [], 'grupo': []
}
# Asignar grupos
grupo_asignado = np.repeat(grupos, num_estudiantes_por_grupo)
random.shuffle(grupo_asignado)
for idx, id_estudiante in enumerate(ids):
fechas = [fecha_inicio + pd.DateOffset(weeks=i*4) for i in range(num_notas)]
notas = np.random.normal(6.5, 1, num_notas).clip(0, 10)
estatura = np.random.uniform(150, 190, num_notas)
sexo = random.choice(['H', 'M'])
# Usamos la nueva función (he puesto correlación 0.75 para que
# sea bien visible)
tiempo_estudio = generar_tiempo_estudio(notas, correlacion=0.75)
for i in range(num_notas):
data['id_estudiante'].append(id_estudiante)
data['asignatura'].append(asignatura)
data['tema'].append(temas[i])
data['fecha'].append(fechas[i])
data['nota'].append(round(notas[i], 2))
if 9 <= notas[i] <= 10: calificacion = 'sobresaliente'
elif 7 <= notas[i] < 9: calificacion = 'notable'
elif 5 <= notas[i] < 7: calificacion = 'aprobado'
else: calificacion = 'suspenso'
data['calificacion'].append(calificacion)
data['estatura'].append(estatura[i])
data['sexo'].append(sexo)
data['tiempo_estudio'].append(tiempo_estudio[i])
data['grupo'].append(grupo_asignado[idx])
df = pd.DataFrame(data)
df['aprobado'] = df['calificacion'].apply(lambda x: 0 if x == 'suspenso' else 1)
# Asegurar orden correcto de temas
orden_temas = [f'Tema {i}' for i in range(1, 11)]
df['tema'] = pd.Categorical(df['tema'], categories=orden_temas, ordered=True)
# Mostrar el DataFrame
print(df)
id_estudiante asignatura tema fecha nota calificacion \
0 XAJI0Y6D Matemáticas Tema 1 2024-09-01 7.00 aprobado
1 XAJI0Y6D Matemáticas Tema 2 2024-09-29 6.36 aprobado
2 XAJI0Y6D Matemáticas Tema 3 2024-10-27 7.15 notable
3 XAJI0Y6D Matemáticas Tema 4 2024-11-24 8.02 notable
4 XAJI0Y6D Matemáticas Tema 5 2024-12-22 6.27 aprobado
... ... ... ... ... ... ...
1595 FNKOMV2X Matemáticas Tema 6 2025-01-19 4.28 suspenso
1596 FNKOMV2X Matemáticas Tema 7 2025-02-16 7.87 notable
1597 FNKOMV2X Matemáticas Tema 8 2025-03-16 5.41 aprobado
1598 FNKOMV2X Matemáticas Tema 9 2025-04-13 7.76 notable
1599 FNKOMV2X Matemáticas Tema 10 2025-05-11 7.45 notable
estatura sexo tiempo_estudio grupo aprobado
0 157.272999 H 357 C 1
1 157.336180 H 256 C 1
2 162.169690 H 274 C 1
3 170.990257 H 185 C 1
4 167.277801 H 236 C 1
... ... ... ... ... ...
1595 173.907293 M 252 A 0
1596 184.787835 M 250 A 1
1597 185.633286 M 299 A 1
1598 167.961510 M 189 A 1
1599 168.372148 M 284 A 1
[1600 rows x 11 columns]
Ahora que tenemos nuestro dataframe con las notas de los alumnos, vamos a crear una tabla de frecuencias de dichas notas y explicaremos los conceptos correspondientes.
# Calcular la tabla de frecuencias
frecuencia_absoluta = df['nota'].value_counts().sort_index()
frecuencia_acumulada = frecuencia_absoluta.cumsum()
frecuencia_relativa = frecuencia_absoluta / frecuencia_absoluta.sum()
frecuencia_relativa_acumulada = frecuencia_relativa.cumsum()
# Crear el DataFrame de la tabla de frecuencias
tabla_frecuencias = pd.DataFrame({
'x_i': frecuencia_absoluta.index, # Columna de notas
'n_i': frecuencia_absoluta.values, # Frecuencia absoluta
'N_i': frecuencia_acumulada.values, # Frecuencia acumulada
'f_i': frecuencia_relativa.values, # Frecuencia relativa
'F_i': frecuencia_relativa_acumulada.values # Frecuencia relativa acumulada
})
# Reiniciar el índice para que comience desde 1
tabla_frecuencias.index = np.arange(1, len(tabla_frecuencias) + 1)
# Mostrar la tabla de frecuencias
print(tabla_frecuencias)
x_i n_i N_i f_i F_i 1 3.48 1 1 0.000625 0.000625 2 3.49 1 2 0.000625 0.001250 3 3.51 1 3 0.000625 0.001875 4 3.56 1 4 0.000625 0.002500 5 3.60 1 5 0.000625 0.003125 .. ... ... ... ... ... 426 9.37 1 1596 0.000625 0.997500 427 9.45 1 1597 0.000625 0.998125 428 9.61 1 1598 0.000625 0.998750 429 9.74 1 1599 0.000625 0.999375 430 10.00 1 1600 0.000625 1.000000 [430 rows x 5 columns]
La tabla que estamos viendo tiene varias columnas. Vamos a revisarlas una por una.
Variable y posición ($x_i$)
# Mostrar la tabla de valores de x_i
print(tabla_frecuencias[['x_i']])
x_i 1 3.48 2 3.49 3 3.51 4 3.56 5 3.60 .. ... 426 9.37 427 9.45 428 9.61 429 9.74 430 10.00 [430 rows x 1 columns]
Esta columna muestra los valores que adopta la variable, en este caso la notas, ordenados de menor a mayor.
El subíndice $i$ nos indica la posición que ocupa ese valor de la variable.
Es muy importante ser consciente de que NO se trata del listado completo de notas, sino de los valores de las mismas.
En el dataframe con las notas, hay 1600 observaciones. Nuestra tabla de frecuencias, tiene 430 filas. Eso quiere decir que, aunque no lo estemos viendo en la tabla resumida (que muestra las 5 primeras posiciones, y las 5 últimas) hay notas que se repiten, cuyo valor aparece en la tabla en una sola fila. Por lo tanto, $i$ indica la posición del valor, como hemos dicho, no el número de observación.
Por ejemplo, $x_3 = 3.51$, y se debe interpretar de la siguiente manera: 3.51 es valor ($x$) que, tras ordenar los datos de menor a mayor, ocupa el tercer puesto.
Comentario: hemos querido introducir la notación con índices lo antes posible, porque para seguir adecuadamente el contenido de artículos posteriores, es bueno ir acostumbrándose a esta notación.
Frecuencia absoluta ($n_i$)
# Mostrar la tabla de valores de x_i y n_i
print(tabla_frecuencias[['x_i', 'n_i']])
x_i n_i 1 3.48 1 2 3.49 1 3 3.51 1 4 3.56 1 5 3.60 1 .. ... ... 426 9.37 1 427 9.45 1 428 9.61 1 429 9.74 1 430 10.00 1 [430 rows x 2 columns]
La frecuencia absoluta indica el número de veces que un valor concreto aparece en el conjunto de datos analizados. En la tabla resumen todos los valores visualizados aparecen una vez, aunque ya hemos dicho que debe haber valores repetidos puesto que de 1600 observaciones, hemos pasado a una tabla con 430 filas.
# Filtrar las observaciones con n_i mayor que 1
filtradas = tabla_frecuencias[tabla_frecuencias['n_i'] > 1]
# Seleccionar solo 10 observaciones
filtradas_10 = filtradas.head(10)
# Mostrar observaciones filtradas
print(filtradas_10[['x_i', 'n_i']])
x_i n_i 12 4.01 2 14 4.20 2 15 4.28 2 19 4.37 3 21 4.42 3 22 4.43 3 26 4.53 2 27 4.54 2 28 4.55 3 29 4.59 3
En la tabla anterior hemos filtrado los datos para mostrar valores de $x$ que se aparecen más de una vez.
$x_{19}$ (4.37), por ejemplo, se repite 3 veces. Esto significa que esa nota concreta aparece tres veces en nuestro dataframe de notas.
Frecuencia absoluta acumulada ($N_i$)
# Mostrar la tabla de valores de x_i y n_i
print(tabla_frecuencias[['x_i', 'n_i', 'N_i']])
x_i n_i N_i 1 3.48 1 1 2 3.49 1 2 3 3.51 1 3 4 3.56 1 4 5 3.60 1 5 .. ... ... ... 426 9.37 1 1596 427 9.45 1 1597 428 9.61 1 1598 429 9.74 1 1599 430 10.00 1 1600 [430 rows x 3 columns]
La frecuencia absoluta acumulada es la suma de las frecuencias absolutas. En esta visualización resumida la frecuencia absoluta acumulada de los primeros 5 valores coincide con el índice $i$, pero esto no pasa cuando el valor de la variable se repite más de una vez:
# Mostrar la tabla de valores de x_i y n_i
print(tabla_frecuencias[['x_i', 'n_i', 'N_i']].head(15))
x_i n_i N_i 1 3.48 1 1 2 3.49 1 2 3 3.51 1 3 4 3.56 1 4 5 3.60 1 5 6 3.85 1 6 7 3.86 1 7 8 3.87 1 8 9 3.91 1 9 10 3.94 1 10 11 4.00 1 11 12 4.01 2 13 13 4.11 1 14 14 4.20 2 16 15 4.28 2 18
Así, la frecuencia absoluta acumulada de $x_{15}$ (4.28) es 18, que resulta de
sumar 2 a 16, que es la frecuencia absoluta acumulada de $x_{14}$ (4.20).
La frecuencia absoluta acumulada nos dice cuántas observaciones tienen un valor igual o inferior a un valor concreto de nuestro conjunto de datos. Es decir, en nuestro dataframe, hay 18 casos en los que la nota obtenida en el examen es igual o inferior a 4.28 ($x_{15}$).
Muy importante: una forma de comprobar si nuestra tabla de frecuencias es correcta, es fijarse en el último valor que adopta la frecuencia absoluta acumulada. Éste debe ser igual al número de observaciones totales. Recordemos que nuestro dataframe de notas tiene 1600 observaciones.
# Mostrar la tabla de valores de x_i y n_i
print(tabla_frecuencias[['x_i', 'n_i', 'N_i']].tail(5))
x_i n_i N_i 426 9.37 1 1596 427 9.45 1 1597 428 9.61 1 1598 429 9.74 1 1599 430 10.00 1 1600
Efectivamente, si vemos los datos correspondientes a las 5 últimas filas de la tabla de frecuencias, comprobamos que el último valor $(x_{430})$, tiene una frecuencia absoluta acumulada de 1600.
Para terminar, mostraremos la fórmula de la frecuencia absoluta acumulada, con el objetivo de irnos familiarizando con la notación matemática que luego veremos en otros artículos:
$$\sum_{i=1}^k n_i = n_1 + n_2 + n_3 +…+ n_k = N$$
En nuestro caso:
$$\sum_{i=1}^k n_i = 1_1 + 1_2 + 1_3 + … + 2_{12} + … 3_{21} + …+ 1_{430} = 1600$$
Frecuencia relativa ($f_i$)
# Mostrar la tabla de valores de x_i, n_i, N_i y f_1
print(tabla_frecuencias[['x_i', 'n_i', 'N_i', 'f_i']].head(15))
x_i n_i N_i f_i 1 3.48 1 1 0.000625 2 3.49 1 2 0.000625 3 3.51 1 3 0.000625 4 3.56 1 4 0.000625 5 3.60 1 5 0.000625 6 3.85 1 6 0.000625 7 3.86 1 7 0.000625 8 3.87 1 8 0.000625 9 3.91 1 9 0.000625 10 3.94 1 10 0.000625 11 4.00 1 11 0.000625 12 4.01 2 13 0.001250 13 4.11 1 14 0.000625 14 4.20 2 16 0.001250 15 4.28 2 18 0.001250
La frecuencia relativa es la proporción de veces que aparece un determinado valor en los datos:
$$n_i/N$$
En otras palabras, es lo que se obtiene al dividir la frecuencia absoluta correspondiente, por el total de observaciones.
Se puede expresar también en tantos por ciento:
$$(n_i/N) * 100$$
Por ejemplo, $x_5$ (3.60), aparece 1 vez. Su frecuencia relativa es
$$1/1600 = 0.000625$$
La nota 3.60, por tanto, aparece el 0.0625% de las veces en el conjunto de datos.
La frecuencia relativa, además, se relaciona estrechamente con otro concepto que veremos más adelante: la probabilidad a priori de obtener una nota igual al valor correspondiente.
Si meto la mano en una bolsa con todas la notas de los exámenes de matemáticas (las 1600), y extraigo una nota al azar, la probabilidad de sacar una papeleta marcada con un 3.60 del 0.000625.
Frecuencia relativa acumulada ($F_i$)
# Mostrar la tabla de valores de x_i, n_i, N_i, f_1 y F_i
print(tabla_frecuencias[['x_i', 'n_i', 'N_i', 'f_i', 'F_i']])
x_i n_i N_i f_i F_i 1 3.48 1 1 0.000625 0.000625 2 3.49 1 2 0.000625 0.001250 3 3.51 1 3 0.000625 0.001875 4 3.56 1 4 0.000625 0.002500 5 3.60 1 5 0.000625 0.003125 .. ... ... ... ... ... 426 9.37 1 1596 0.000625 0.997500 427 9.45 1 1597 0.000625 0.998125 428 9.61 1 1598 0.000625 0.998750 429 9.74 1 1599 0.000625 0.999375 430 10.00 1 1600 0.000625 1.000000 [430 rows x 5 columns]
La frecuencia relativa acumulada, es la suma de las frecuencias relativas:
$$\sum_{i=1}^k f_i = f_1 + f_2 + f_3 +…+ f_k = n_i/N = 1$$
La frecuencia relativa acumulada de $x_k$, siendo éste el último valor, debe ser igual a 1.
La frecuencia relativa acumulada nos dice la proporción (o el porcentaje) de observaciones en las que el valor de $x$ es igual o menor que un valor determinado.
Así, por ejemplo, el 99.75% de las notas son iguales o menores que 9.37 ($x_{426}$).
También podríamos decir que la probabilidad de sacar de una cesta con todas las notas una papeleta marcada con una nota igual o inferior a 9.37, es del 99,75%.
Datos agrupados
Si las variables toman un gran número de valores, como es nuestro caso con las notas (recordemos, hay 430 valores distintos) es útil agrupar los datos para tener una visión más simple o resumida de lo que está sucediendo.
Supongamos, por ejemplo, que nos interesa saber las notas en intervalos de 0 a 1, de 1 a 2, de 2 a 3, de 3 a 4…
Esto, ciertamente, hará que nuestra tabla de frecuencias sea mucho más resumida. Si la nota mínima es 0 y la máxima es 10, podremos agrupar los datos en, por ejemplo, 10 contenedores.
Ahora bien, debemos elegir bien el número de grupos. Una de las reglas básicas es que cada grupo o contenedor (bin) suelen tener el mismo ancho. Pero además, debemos asegurarnos de no perder demasiada información, evitando construir contenedores que no tengan datos dentro de ellos.
Si hacemos un sólo grupo de 0 a 10 la tabla de frecuencias será inútil. Tampoco obtendremos muchas conclusiones interesantes con dos o tres grupos. Si, por el contrario, creamos demasiados grupos, tendremos un problema similar al de la tabla original con datos sin agrupar: demasiadas filas con frecuencias muy pequeñas, y una situación general muy difícil de interpretar.
La selección correcta del número de grupos está entre el arte y la ciencia, y depende de los datos, y de la manera en la que queramos analizar dichos datos.
Procedimiento para construir una tabla de frecuencias con datos agrupados
El procedimiento para construir una frecuencia de datos agrupada, descrito por Jhonson & Kubi, es el siguiente:
Paso 1: «Identifique el valor más alto, y el valor más bajo que toma la variable«:
# Obtener los valores mínimos y máximos de la columna 'A'
valor_minimo = df['nota'].min()
valor_maximo = df['nota'].max()
print("Valor mínimo en la columna 'nota':", valor_minimo)
print("Valor máximo en la columna 'nota':", valor_maximo)
Valor mínimo en la columna 'nota': 3.48 Valor máximo en la columna 'nota': 10.0
Paso 2: «Calcule el rango (la resta entre el valor máximo y el mínimo)«:
rango = valor_maximo - valor_minimo
print("Rango de la columna 'nota':", rango)
Rango de la columna 'nota': 6.52
Paso 3: «Seleccione un número de grupos ($g$) y un ancho de grupo ($a$) de modo que el producto ($ga$) sea un poco mayor que el rango*».
Aquí empieza un poco el arte, porque esa condición a menudo la podemos conseguir de varias maneras (y no está claro qué se entiende por «un poco mayor que el rango«…).
Por ejemplo, en nuestro caso, hemos visto que el rango de notas es 6.52. La opción más adecuada parece ser
- 7 grupos de ancho 1 ($g*a = 7 * 1 = 7$), aunque también podríamos trabajar con 4 grupos de ancho 2.
Vamos a apostar por la primera opción. 7 grupos de ancho 1 seguramente serán más informativos que 4 grupos de ancho 2. Además, y como veremos más adelante, suele ser conveniente seleccionar un número impar de contenedores.
num_grupos = 7
ancho_grupo = 1
print("Número de grupos:", num_grupos)
print("Ancho de cada grupo:", ancho_grupo)
print("g*a = ", num_grupos*ancho_grupo)
Número de grupos: 7 Ancho de cada grupo: 1 g*a = 7
Paso 4: «Seleccione un punto inicial; éste debe ser un poco menor que la calificación más baja«.
De nuevo, aquí las cosas quedan un poco al criterio del analista. Qué es «un poco menor a la calificación más baja«?
«Si la nota más baja es 3.48, una buena elección como punto inicial podría ser 3.45. Si partimos de ahí, y los saltos son de 1 (el acho de grupo seleccionado), ya podemos definir las fronteras de grupo«:
3.45, 4.45, 5.45, 6.45, 7.45, 8.45, 9.45, 10.45
Recordemos que la nota más baja es 3.48, y la más alta un 10, así que todas las notas están dentro de las fronteras inferior y superior del primer y último grupo, respectivamente.
punto_inicial = 1.95
- 3.45 o más a menos de 4.45 -> $3.45 \leq \ x < 4.45$
- 4.45 o más a menos de 5.45 -> $4.45 \leq \ x < 5.45$
- 5.45 o más a menos de 6.45 -> $5.45 \leq \ x < 6.45$
- 6.45 o más a menos de 7.45 -> $6.45 \leq \ x < 7.45$
- 7.45 o más a menos de 8.45 -> $7.45 \leq \ x < 8.45$
- 8.45 o más a menos de 9.45 -> $8.45 \leq \ x < 9.45$
- 9.45 o más a menos de 10.45 -> $9.45 \leq \ x < 10.45$
Una vez definidos los grupos de esta forma, ya podemos generar nuestra tabla de frecuencias con datos agrupados:
# Definir los contenedores de notas
bins = [3.45, 4.45, 5.45, 6.45, 7.45, 8.45, 9.45, 10.45]
labels = ["[3.45, 4.45)", "[4.45, 5.45)", "[5.45, 6.45)", "[6.45, 7.45)", "[7.45, 8.45)", "[8.45, 9.45)", "[9.45. 10.45)"]
# Crear una nueva columna 'contendor' para asignar las notas a los contenedores
df['contenedor'] = pd.cut(df['nota'], bins=bins, labels=labels, right=False)
# Calcular la tabla de frecuencias para los contenedores
frecuencia_absoluta = df['contenedor'].value_counts().sort_index()
frecuencia_acumulada = frecuencia_absoluta.cumsum()
frecuencia_relativa = frecuencia_absoluta / frecuencia_absoluta.sum()
frecuencia_relativa_acumulada = frecuencia_relativa.cumsum()
# Crear el DataFrame de la tabla de frecuencias
tabla_frecuencias_agrupadas = pd.DataFrame({
'x_i': frecuencia_absoluta.index, # Contenedores de notas
'n_i': frecuencia_absoluta.values, # Frecuencia absoluta
'N_i': frecuencia_acumulada.values, # Frecuencia acumulada
'f_i': frecuencia_relativa.values, # Frecuencia relativa
'F_i': frecuencia_relativa_acumulada.values # Frecuencia relativa acumulada
})
# Reiniciar el índice para que comience desde 1
tabla_frecuencias_agrupadas.index = np.arange(1, len(tabla_frecuencias_agrupadas) + 1)
# Mostrar la tabla de frecuencias
print(tabla_frecuencias_agrupadas)
x_i n_i N_i f_i F_i 1 [3.45, 4.45) 32 32 0.020000 0.020000 2 [4.45, 5.45) 219 251 0.136875 0.156875 3 [5.45, 6.45) 535 786 0.334375 0.491250 4 [6.45, 7.45) 539 1325 0.336875 0.828125 5 [7.45, 8.45) 230 1555 0.143750 0.971875 6 [8.45, 9.45) 41 1596 0.025625 0.997500 7 [9.45. 10.45) 4 1600 0.002500 1.000000
Como podemos ver, nuestra tabla de frecuencias original, de 430 filas, ha quedado reducida a una tabla de 7 filas.
Cada grupo tiene datos (no hay grupos vacíos), y podemos sacar conclusiones a partir de ella. Por ejemplo, y si redondeamos, podemos decir que:
- Entre 6.5 y el 7.5 hay 539 notas, que suponen el 33,69% del total (fila 4)
- El 99,75% de las notas son inferiores a 9.45 (fila 6)
- Solo hay 4 notas iguales o superiores al 9.45, lo que representa un escaso 0.25%
- La mayor concentración de notas está entre 5.5 y 7.5, (filas 3 y 4).
- Suspendidos sin remisión hay 32 exámenes, un 2%.
Nota: es importante darse cuenta de que ahora $x_i$ no es el valor que ocupa la posición $i$, si no el grupo, intervalo o contenedor que ocupa esa posición.
Representación gráfica
Como ya vimos en el primer artículo de esta serie, adelantando un poco lo que contaremos ahora, la distribución o frecuencia de las variables discretas, o discretizadas, se representan mediante histogramas.
Un histograma es un gráfico similar al de barras (adecuado para variables cualitativas o categóricas), en el que las barras están juntas (sin espacios entre ellas).
En el eje $x$ vemos los rangos de valores, y en el eje $y$ su frecuencia absoluta($n_i$). Veamos un ejemplo, usando el dataframe de notas:
import seaborn as sns
import matplotlib.pyplot as plt
# Definir los bordes de los bins
bins = np.linspace(0, 10, 21) # 21 porque queremos 20 intervalos
# Imprimir los bordes de los bins
print("Bordes de los bins:", bins)
# Graficar el histograma de las notas usando Seaborn
plt.figure(figsize=(10, 6))
sns.histplot(data=df['nota'], bins=bins, kde=False, color='blue')
plt.title('Distribución de Notas de la Población')
plt.xlabel('Nota')
plt.ylabel('Frecuencia')
plt.show()
Bordes de los bins: [ 0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5 6. 6.5 7. 7.5 8. 8.5 9. 9.5 10. ]

Tal y como hemos definido este histograma, las notas se agrupan en 21 contenedores o grupos (20 intervalos), en saltos de 0.5, y teniendo en cuenta que el rango es de 10 (las notas van de 0 a 10).
Si nos fijamos, aunque hemos definido 21 contenedores para visualizar 20 intervalos, solo se aprecian 14 barras. Esto es porque en nuestro conjunto de datos, como hemos visto, no hay notas en los intervalos
- [0.0, 0.5)
- [0.5, 1.0)
- [1.0, 1.5)
- [1.5, 2.0)
- [2.0, 2.5)
- [2.5, 3.0)
Aún así, la visualización no está tan mal. Afecta a contenedores en los extremos, y no vemos huecos entre las barras.
Pero, ¿es la visualización óptima?
¿Qué pasa si queremos ver más contenedores, disminuyendo su ancho?
# Definir los bordes de los bins del tamaño de 0.1
bins = np.arange(0, 10.1, 0.1)
# Graficar el histograma de las notas usando Seaborn
plt.figure(figsize=(10, 6))
sns.histplot(data=df['nota'], bins=bins, kde=False, color='blue')
plt.title('Distribución de Notas de la Población')
plt.xlabel('Nota')
plt.ylabel('Frecuencia')
plt.show()

¿Cuál de los dos gráficos es mejor?
Es necesario advertir que ambos gráficos están desplazados hacia la derecha, porque hemos obligado a Python a incluir intervalos que empiezan desde cero.
Procedimiento para seleccionar el número óptimo de contenedores para un histograma
Como hemos visto, seleccionar correctamente el número de grupos y su ancho no es una ciencia exacta y, fuera de las reglas básicas, depende mucho del criterio del analista.
Si queremos tomar una decisión rápida, sobre todo a la hora de graficar los datos mediante histogramas, podemos determinar el número de grupos o contenedores a través de los métodos de la raíz cuadrada o el criterio de Sturges.
Raíz cuadrada
Este método es muy sencillo: consiste en calcular la raiz cuadrada del número de observaciones ($N$). Ése será el número de grupos o contenedores que usaremos ($g$).
$$g = \sqrt{N}$$
Este método sirve solo en casos en los que hay relativamente pocas observaciones («menos de 125 datos«, según Johnson & Kuby).
Criterio de Sturges
Cuando el número de observaciones es grande (más de 125 observaciones), podemos usar el criterio de Sturges. Según este criterio, el número de grupos óptimo a la hora de crear contenedores o grupos se calcula mediante la siguiente expresión:
$$g = 1 + \log_2(N)$$
El número de grupos ($g$) debe redondearse a un número entero. Si el valor entero es par, se redondea al alza. Si es impar, se redondea a la baja. Esto genera un número impar de contenedores, lo que permite ver la acumulación cerca de la media en una distribución normal.
En el caso de las notas, donde tenemos 1600 observaciones ($N$), deberíamos usar este criterio.
import math
N = 1600
resultado = 1 + math.log2(N)
print(resultado)
11.643856189774725
Según este resultado, el número óptimo de contenedores o grupos ($g$) es 11, pero en nuestra tabla de frecuencias usamos 7 contenedores… ¿En qué quedamos?
Es importante entender que no es lo mismo mostrar los datos en una tabla, que en un histograma. Ambas cosas son para fines distintos.
Por ejemplo, en la tabla, el método que hemos usado nos ha permitido hacer saltos de ancho 1, cosa que con las notas es algo lógico.
Con 11 contenedores, y con notas de 0 a 10, los contenedores tendrían un ancho de:
$$rango/g = 10/11 = 0.9090 \approx 0.91$$
El rango en nuestro caso concreto es, aproximadamente, de 7, por lo que tendríamos contenedores de ancho:
$$rango/g = 7/11 = 0.6363 \approx 0.64$$
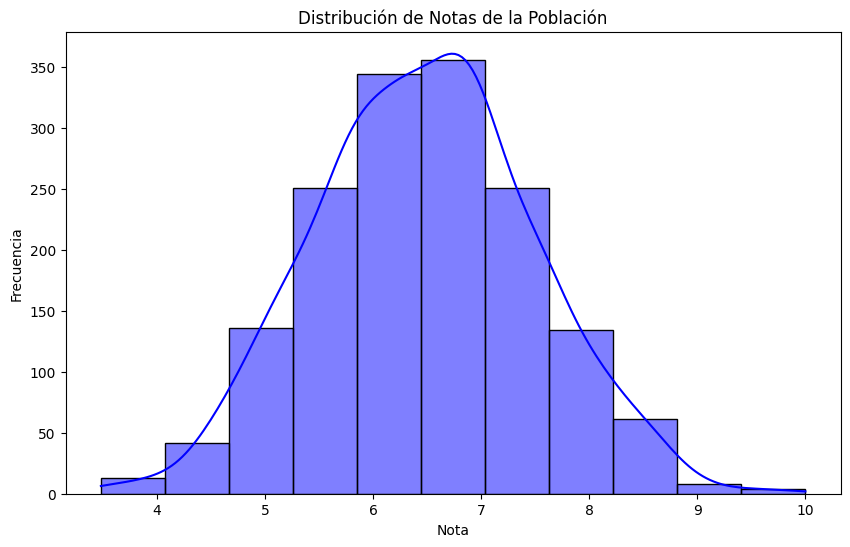
Ninguno de estos «saltos» nos permitiría construir una tabla «limpia» y fácil de entender. Pero quizá, y solo quizá, 11 contenedores es el número mágico que necesitamos para pintar un histograma adecuado. Vamos a verlo.
El siguiente gráfico muestra los datos agrupados en 11 intervalos, para un rango de 0 a 10, con saltos de 0.91:
# Graficar el histograma con 11 contenedores sin forzar bordes específicos
plt.figure(figsize=(10, 6))
sns.histplot(data=df['nota'], bins=11, kde=False, color='blue')
plt.title('Distribución de Notas de la Población')
plt.xlabel('Nota')
plt.ylabel('Frecuencia')
plt.show()

Aunque los saltos no son limpios, la visualización sí lo es. Nos permite ver que las notas se concentran en torno al 6.5, y que a medida que nos desplazamos hacia los extremos, tanto a izquierda como a derecha, la frecuencia disminuye.
En ocasiones no es tan fácil dar con el número correcto de contenedores, y los histogramas pueden hacernos perder información. Esto suele ocurrir con más frecuencia cuando la variable es numérica discreta, pero en realidad es continua y ha sido discretizada o, siendo discreta, tiene decimales (recomendamos aquí repasar el primer artículo de esta serie, sobre todo el apartado referido a tipos de variables).
Por estas razones, y cuando lo que se quiere es visualizar el tipo de distribución que tienen los datos, es frecuente ver que en lugar de los histogramas se usa el de densidad, o una mezcla de ambos (el histograma, y la curva de densidad correspondiente).
La ventaja de los gráficos de densidad, que se toman la licencia de considerar como continuas las variables, es que suavizan la forma y nos permiten visualizar la distribución sin necesidad de calcular los contenedores y su ancho óptimo.
# Graficar el histograma con 11 contenedores sin forzar bordes específicos
plt.figure(figsize=(10, 6))
sns.histplot(data=df['nota'], bins=11, kde=True, color='blue')
plt.title('Distribución de Notas de la Población')
plt.xlabel('Nota')
plt.ylabel('Frecuencia')
plt.show()

Este tipo de visualizaciones es muy útil para determinar el tipo de distribución de datos. Y saber el tipo de distribución de los datos es esencial en las etapas posteriores de este viaje.
Antes de terminar, vamos a mostrar los tipos de distribuciones comunes, que veremos con más detalles más adelante.
Tipos de distribuciones
Para terminar, vamos a mostrar, a modo de introducción, algunos tipos de distribuciones comunes. Nos encontraremos con ellas muchas veces, y cada una tiene sus propiedades. En esta fase, sólo vamos a visualizarlas.
Distribución normal
Ésta, por varias razones, es la reina de las distribuciones. Ya la hemos visto en los ejemplos anteriores y tiene la forma de campana que todos los analistas quieren ver.
# Graficar el histograma con 11 contenedores sin forzar bordes específicos
plt.figure(figsize=(10, 6))
sns.histplot(data=df['nota'], bins=11, kde=True, color='blue')
plt.title('Distribución de Notas de la Población')
plt.xlabel('Nota')
plt.ylabel('Frecuencia')
plt.show()
Distribución uniforme
Es el gráfico que vemos cuando la distribución de los datos es aproximadamente la misma para todos los casos.
# Generar datos con distribución uniforme
data = np.random.uniform(0, 1, 1000)
# Crear el histograma con Seaborn
plt.figure(figsize=(10, 6))
sns.histplot(data, bins=30, kde=True, color='blue', edgecolor='black')
plt.title('Histograma de Datos con Distribución Uniforme')
plt.xlabel('Valor')
plt.ylabel('Frecuencia')
plt.grid(True)
plt.show()

Distribución sesgada a la derecha
# Generar datos con distribución exponencial (sesgada a la derecha)
data_sesgada = np.random.exponential(scale=1, size=1000)
# Crear el histograma con Seaborn
plt.figure(figsize=(10, 6))
sns.histplot(data_sesgada, bins=30, kde=True, color='blue', edgecolor='black')
plt.title('Histograma de Datos Sesgados a la Derecha')
plt.xlabel('Valor')
plt.ylabel('Frecuencia')
plt.grid(True)
plt.show()

Distribución sesgada a la izquierda
# Generar datos con distribución exponencial y luego invertirlos para sesgo a la izquierda
data_sesgada_izquierda = -np.random.exponential(scale=1, size=1000)
# Crear el histograma con Seaborn
plt.figure(figsize=(10, 6))
sns.histplot(data_sesgada_izquierda, bins=30, kde=True, color='blue', edgecolor='black')
plt.title('Histograma de Datos Sesgados a la Izquierda')
plt.xlabel('Valor')
plt.ylabel('Frecuencia')
plt.grid(True)
plt.show()

Existen otras distribuciones, pero ya entraremos en detalles tanto sobre las que aquí hemos mostrado, como sobre algunas que aún no hemos visto.
Bibliografía y referencias
- Johnson, R. & Kuby, P. (2008). Estadística elemental: lo esencial (10a ed.). Cengage Learning Editores S.A.
- Freedman, D., Pisani, R., & Purves, R. (2007). Statistics (4a ed.). WW Norton.
Artículo siguiente: Medidas de tendencia central —>
Artículo anterior: <— Población, muestra, experimentos y tipos de variables