
Raúl Galve
El problema de los costes variables en BigQuery
Nadie duda a día de hoy de que BigQuery es una magnífica herramienta que nos permite trabajar con cantidades enormes de datos, con unos tiempos de respuesta muy buenos y desentendiéndonos de los detalles de la infraestructura subyacente necesaria para almacenar y analizar dichos datos.
Además, la barrera de entrada a nivel económico es nula, dado que BigQuery nació como una herramienta de pago por uso. Nada de costosas cuotas mensuales o anuales que no estamos seguros, de partida, de si seremos capaces de amortizar.
Pero esta ventaja, por otro lado, se convierte en una desventaja cuando nos encontramos que, en el mundo empresarial, cada departamento trabaja con unos presupuestos que deben establecerse de antemano. Debemos ser capaces de estimar los costes que nos van a suponer las herramientas que empleamos para desarrollar nuestro trabajo.
Y esto es (era) muy difícil de hacer en el caso que nos ocupa.
Gracias a los informes de gastos y las alertas de Google Cloud tenemos bastante control sobre el consumo que se va realizando.
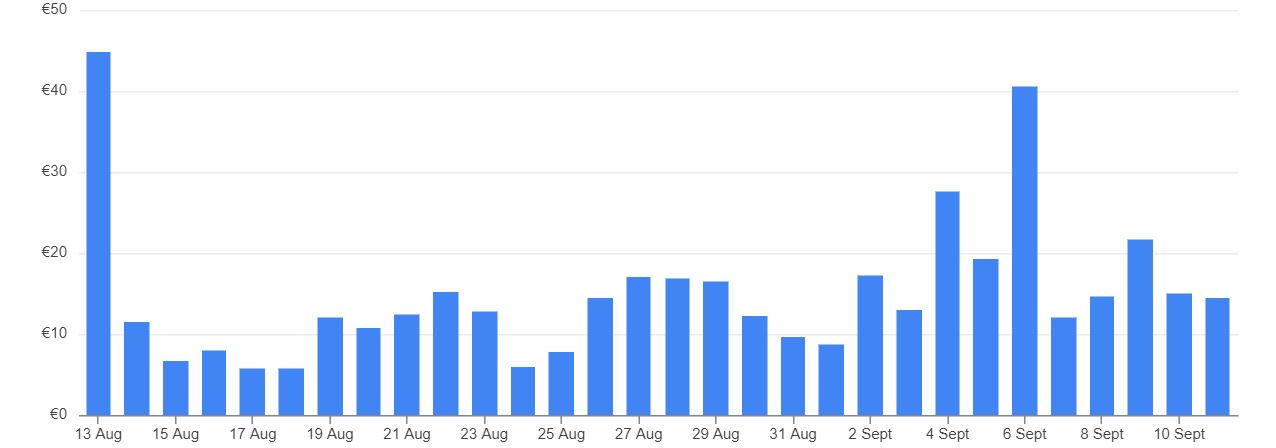
Fig.1: Ejemplo de consumo por día en los informes de facturación de Google Cloud
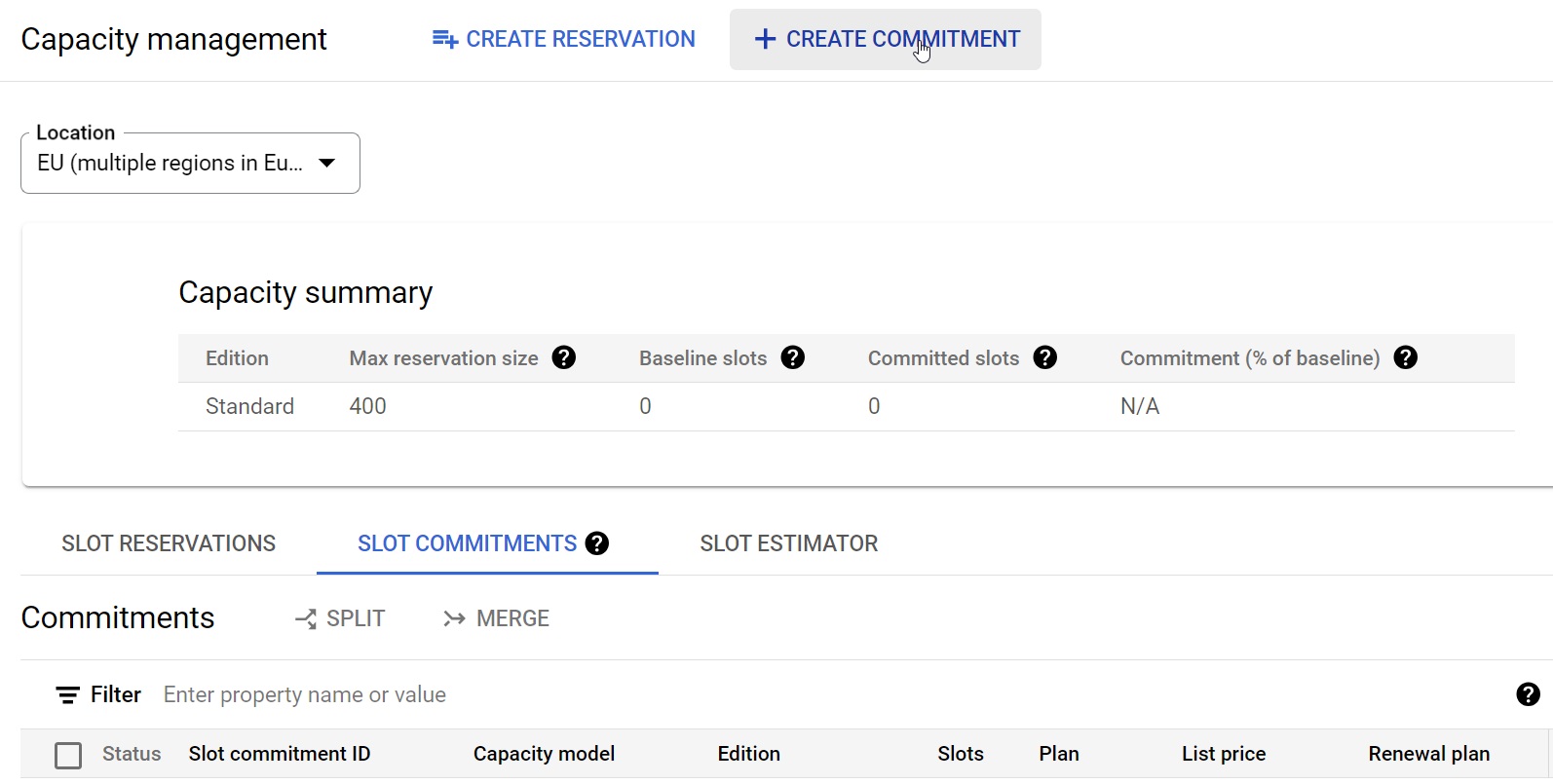
Fig.2: Creación de alertas de gasto
Pero esto no impide que nos podamos llevar algún susto. Decíamos que BigQuery es capaz de trabajar con cantidades enormes de datos con tiempos de respuesta muy buenos. Y también hemos dicho que nos permitía desentendernos de cómo lo hace y de qué recursos utiliza. Pero vale la pena que veamos un poco “las tripas” de esta herramienta.
Esos tiempos de respuesta son gracias a su capacidad de paralelizar el trabajo poniendo a procesar los datos a todos los recursos disponibles para ello.
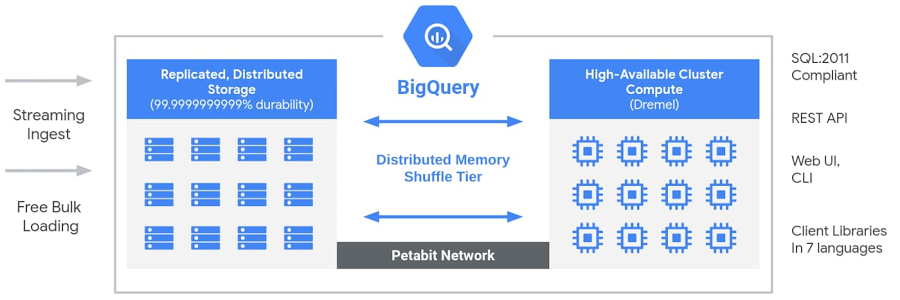
Fig.3: Arquitectura de BigQuery (fuente cloud.google.com).
Aquí es donde viene el problema. Ante una consulta muy compleja y/o sobre una cantidad muy grande de registros, Google puede llegar a utilizar una cantidad enorme (hablamos de miles) de máquinas y esto puede ocasionar picos de gasto como los de la siguiente imagen. A partir de ahora, nos referiremos a dichas máquinas como lo hace Google: ranuras (o slots, en inglés).
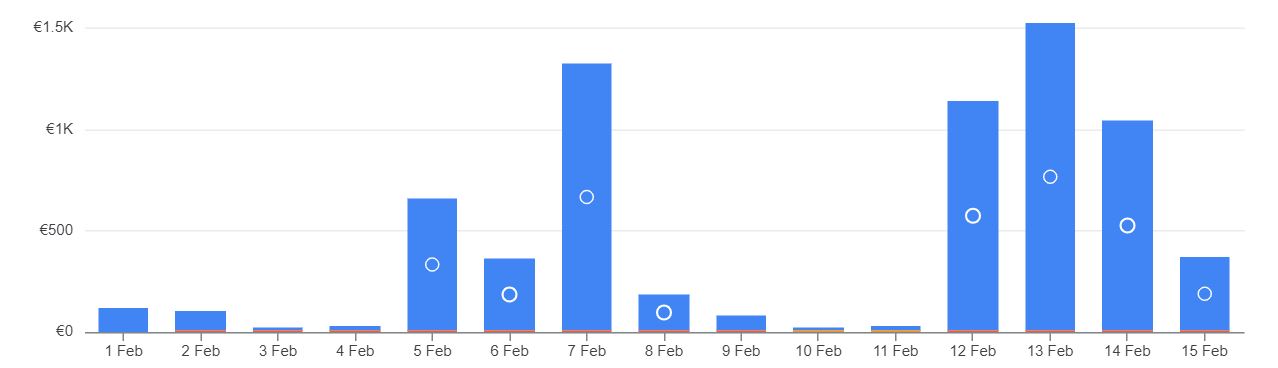
Fig.4: Picos de gasto de BigQuery
En este caso, mientras que en los días de menos gasto teníamos unos consumos más o menos regulares, asociados al refresco de las fuentes de datos de los cuadros de mando y los procesos ETL nocturnos habituales, los días de más consumo fueron aquellos en los que se realizaron ciertos análisis extraordinarios o se trabajó de una manera intensa con algunos cuadros de mando, aplicando filtros y cambios de periodo constantes y forzando numerosos refrescos adicionales de sus fuentes de datos en BigQuery.
Con lo que ha costado instaurar una cultura del dato en las empresas, tampoco es cuestión ahora de meterles miedo o limitarlos en el uso que pueden hacer de BigQuery..
¿Cuál es la solución entonces? Si no hablamos de consultas que deban dar resultados en tiempo real (o casi) y nos podemos permitir que las consultas de BigQuery tarden un poco más en terminar (procesos ETL nocturnos, cuadros de mando de consulta semanal o mensual, etc.) podemos limitar los costes utilizando una reserva de recursos en BigQuery.
Modalidades de servicio en BigQuery
En primer lugar tenemos la clásica, la de pago por uso y que nos hace complicado estimar costes mensuales y establecer un presupuesto.
En verano de 2023, Google añadió otra modalidad con tres niveles.
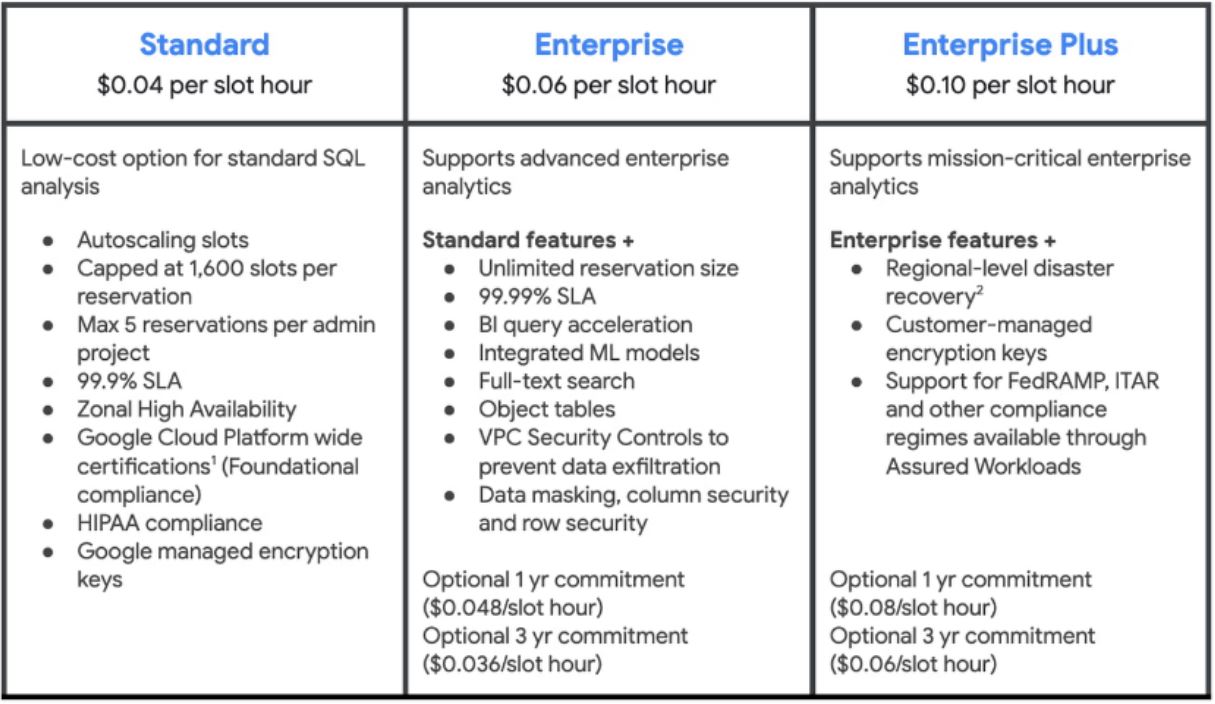
Fig.5: Modalidades de BigQuery. Fuente Google
El modo ediciones, con su asignación de recursos máximos y mínimos para hacer esa paralelización en las consultas, facilita a Google el dimensionamiento de sus centros de procesado de datos y, en contrapartida, repercute en el usuario en un mejor precio del servicio.
Es decir, con esta modalidad no sólo sabemos que no vamos a poner en marcha todas las ranuras (las máquinas) posibles en un determinado momento, sino que, además, el precio por uso de las que utilicemos es más bajo.
Cómo configurar una reserva de recursos en BigQuery
Estas modalidades no son algo a nivel contractual. Están disponibles a nivel de configuración en la consola de Google Cloud y podemos ir haciendo cambios en las reservas de recursos a medida que las vayamos necesitando.
Por ejemplo, en nuestro caso, tras una configuración inicial basada en el análisis del uso previo, hacemos, en días y semanas posteriores, ajustes en la reserva de recursos de un proyecto hasta que encontramos la configuración perfecta que nos permitiera un equilibrio entre el control de gasto y el rendimiento de cara a los usuarios.
Hablando de esto, para configurar una reserva de recursos o modificar/borrar una existente, tenemos que ir al apartado de Administración de BigQuery.
Fig.6: Menú de BigQuery.
En el apartado de Supervisión podemos ver los valores medio y pico (p99) de consumo de ranuras que hemos tenido recientemente, lo que nos podrá dar una idea de la cantidad de recursos con los que podemos trabajar sin afectar demasiado a los usuarios.
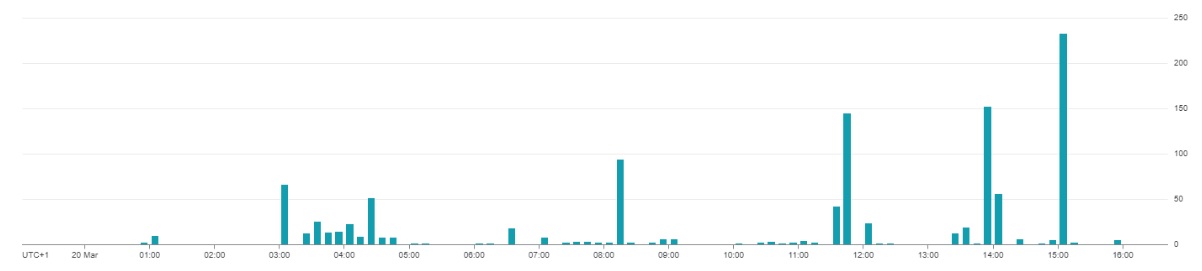
Fig.7: Uso medio de slots o ranuras por franja horaria
Vemos un uso continuado medio de hasta 50-60 ranuras durante los procesos ETL nocturnos y un uso variable a lo largo de la jornada laboral. También podemos visualizar en la gráfica los picos puntuales con muchas más ranuras en uso, que son los que provocan que se nos pueda descontrolar un poco el gasto.
Visto eso, en este caso, podríamos hacer una reserva de un máximo de 100 slots, por ejemplo. Los procesos nocturnos no se verían afectados. Y si tardaran más en terminarse, tampoco nos importaría, ya que se realizan fuera del horario de trabajo.
Durante el día, lo que percibirían los usuarios es que los cuadros de mando tardan un poco más en responder cuando una actualización de sus datos se podría paralelizar más allá del límite que hemos establecido y que antes no tenían. Dichos cuadros, como los realizados con Looker Studio, pueden minimizar el impacto de ésto gracias a la caché que realizan de las fuentes de datos. No es necesario que cada vez que se abra el cuadro se lance una nueva consulta a las tablas subyacentes.
Veamos cómo se configuraría dicha reserva desde el menú de Administración de la capacidad:
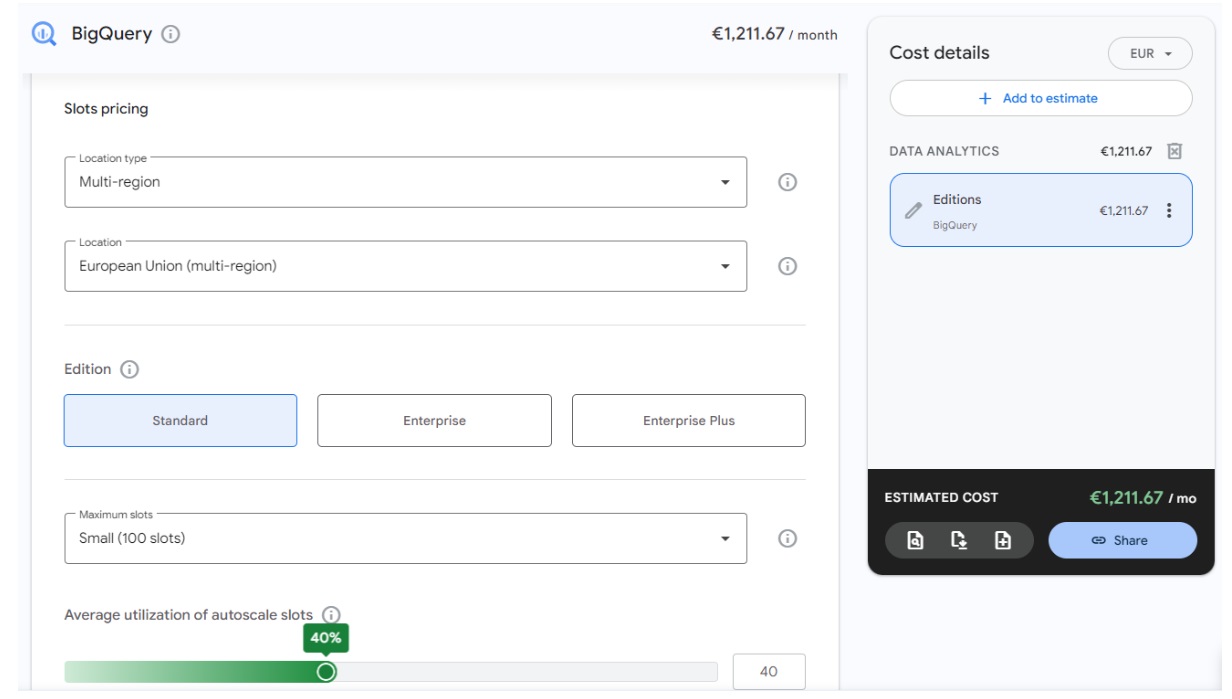
Fig.8: “Anatomía” de una reserva de recursos
Aquí, el ahorro viene por dos frentes:
- Estamos definiendo una reserva multiregional. Es decir, le estamos permitiendo a Google que, cuando requiramos recursos, pueda buscarlos en cualquier centro de datos, en este caso, de Europa. Eso abarata costes con respecto a especificar un centro de datos concreto..
- Estamos estableciendo un límite de uso simultáneo de 100 ranuras o slots. Es el mínimo y podemos aumentarlo en cualquier momento hasta cantidades mucho mayores, de varios miles. Cuando se intente paralelizar una tarea, Google sabe que podrá hacerlo hasta ese límite.
Si nos fijamos en la parte derecha, hablamos de una estimación. Seguimos sin un coste fijo mensual, pero sabemos que el coste no pasará de un límite.
Ese límite lo dará el mover la barra inferior hasta el 100%. Tan solo sirve para decirle a la estimación que nos saque el coste de lo que implicaría tener esas ranuras en uso el 20%, el 40% o el 100% del tiempo total del periodo.
Por ejemplo, en este caso, para una reserva de un máximo de 100 ranuras o slots en europa / multiregión, tendríamos estos escenarios:
Escenarios:
- Óptimo (utilización del 20%) -> Consumo mensual de 620€
- Medio (utilización del 40%) -> Consumo mensual de 1.200€
- Peor (utilización del 100%) -> Consumo máximo absoluto con ese límite de 100 ranuras de 3.000€
En la práctica, en ese proyecto estamos rondando siempre ese 40% de utilización, que es el porcentaje del día que duran los procesos nocturnos más la jornada laboral.
Impacto en el funcionamiento de BigQuery
Muy sencillo. Supongamos que una consulta bastante pesada y cuyo procesado podría dividirse entre 1000 máquinas (slots o ranuras) al mismo tiempo tarda 5 segundos en devolver resultados.
Si hemos puesto un límite de 200 ranuras, por ejemplo, esa consulta no podrá paralelizarse tanto y, simplificando, tardará 5 veces más, 25 segundos.
Este incremento no afectará por igual a todas las consultas o procesos, por supuesto, dado que muchos de ellos no hubieran necesitado de más de 200 ranuras para empezar.
En cualquier caso, la reserva se puede realizar por proyecto o, incluso, por tipo de tarea, por lo que siempre podríamos permitir que parte de nuestro trabajo con BigQuery siga teniendo “barra libre”.
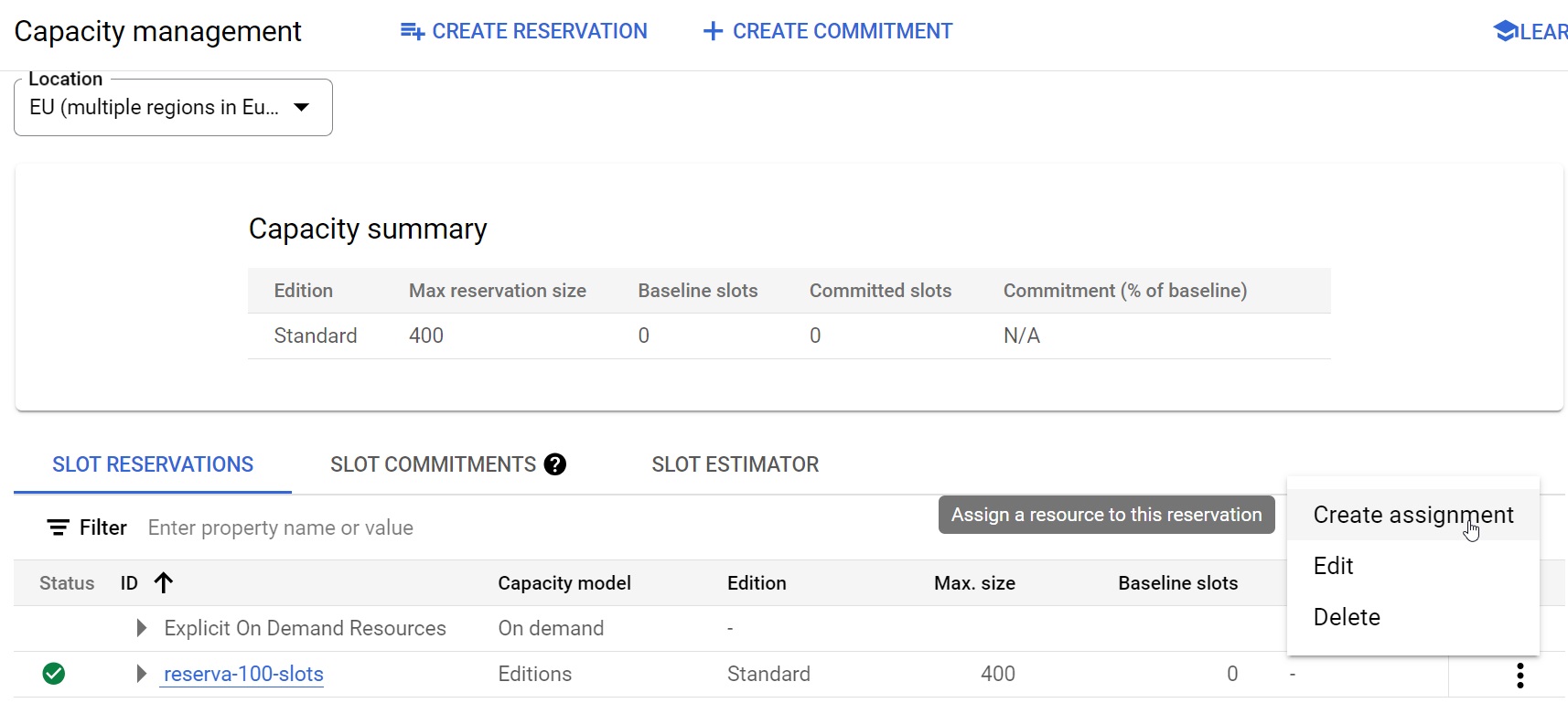
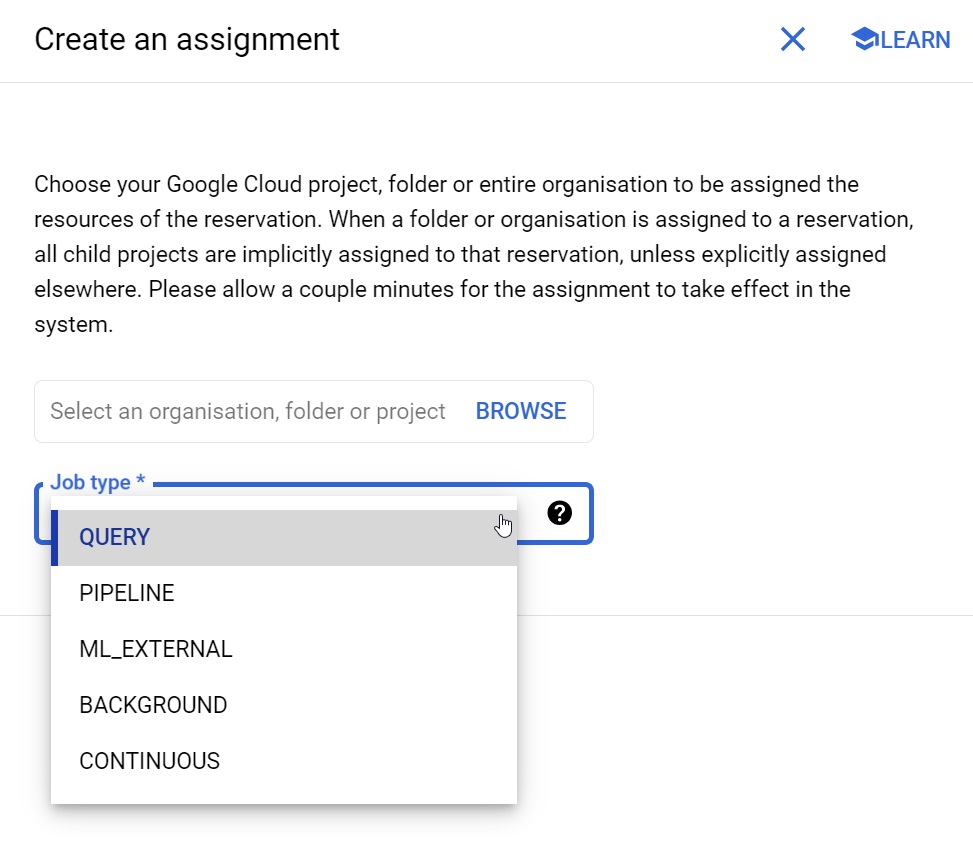
Fig.9: Asignación de una reserva a un proyecto y tipo de tarea en concreto
Si tras una estimación y reserva inicial vemos que no tenemos mucho tiempo las ranuras ocupadas y/o si los usuarios se quejan mucho de los tiempos de espera, siempre podemos editar su configuración y seleccionar un número mayor de recursos. A efectos de estimación, tiene el mismo coste usar un máximo de 200 ranuras un 40% del tiempo que un máximo de 400 el 20%.
Por el lado contrario, si nos preocupa el rendimiento, uno de los factores que impactan en el tiempo que tarda una consulta en ejecutarse es también lo que tarde BigQuery en encontrar recursos disponibles para empezar a procesar nuestros datos. Aquí, y de una manera muy similar, lo que podemos hacer es reservar un mínimo de slots o ranuras que siempre estarán disponibles para nosotros en todo momento.
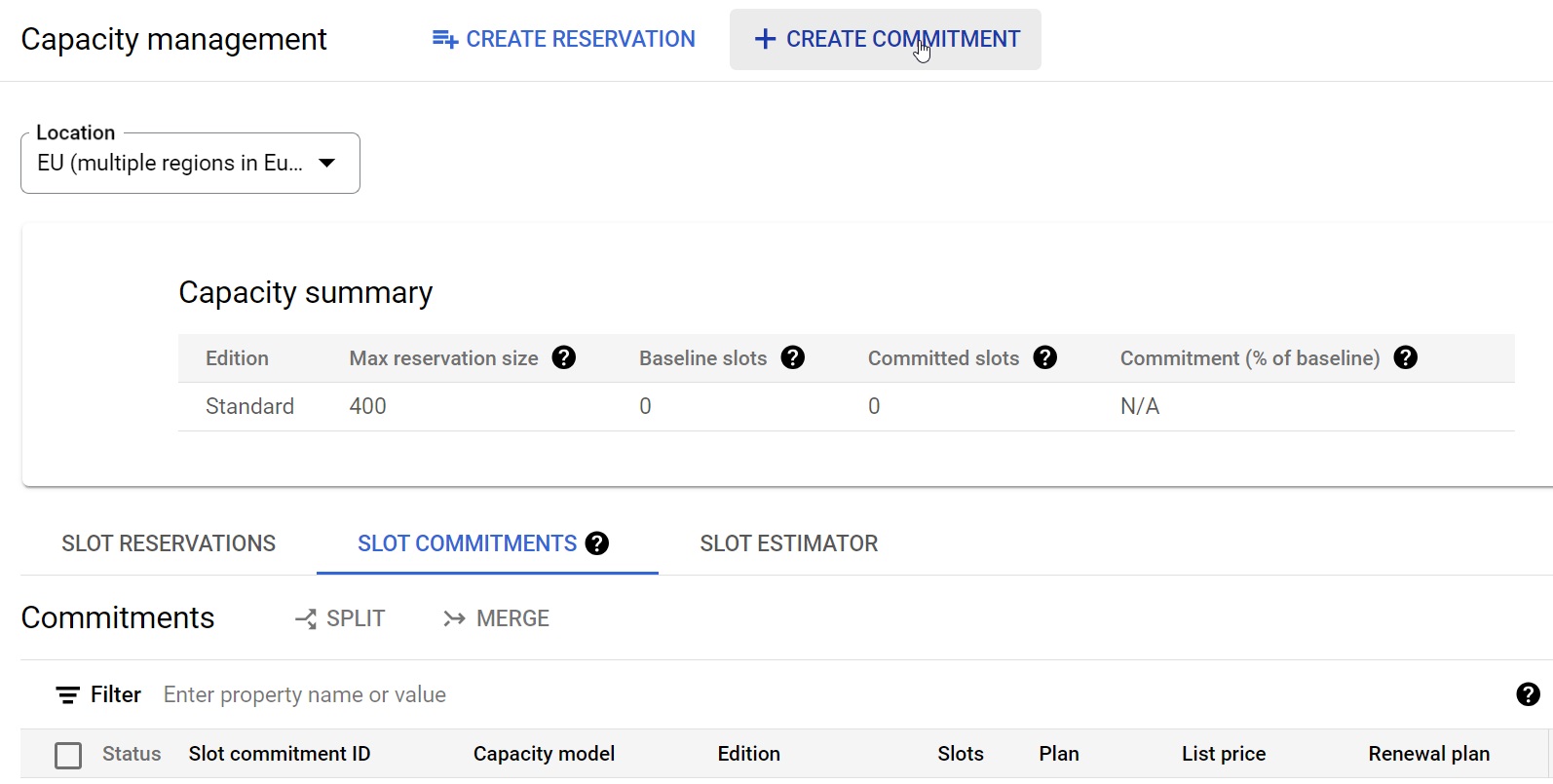
Fig.10: Reserva de recursos siempre disponibles
Pese a esa exclusividad, si realmente vamos a necesitarla y a hacer un uso intensivo de esos recursos, seguimos teniendo precios más atractivos que los del pago por uso. Tengamos en cuenta lo que dijimos, que esto facilita a Google el dimensionar sus centros de datos. En este caso, así como para los recursos máximos podemos hacer cambios en cualquier momento, para esta reserva de recursos mínimos en exclusividad, tenemos periodos mínimos de 1 o 3 años.
Conclusiones y un ejemplo de optimización de costes
Empecemos con el ejemplo real de un proyecto en el que los costes por uso de BigQuery estaban siendo altos para el cliente y, sobre todo, eran poco predecibles.
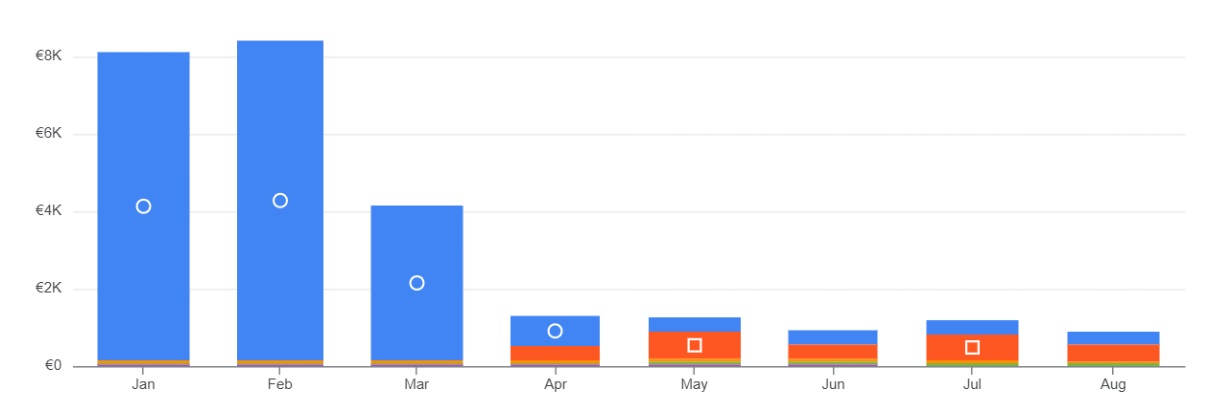
Fig.11: Ejemplo de evolución del gasto en Google Cloud
Si en la gráfica se ven más o menos constantes durante enero y febrero, era porque cuando saltaba la alerta de gasto se “ataba en corto” a los usuarios. Y no queremos vernos obligados a tener el Ferrari parado en el garaje por haber agotado el presupuesto para gasolina. Queremos optimizar el consumo y poder conducir durante todo el mes.
Para ello, a finales de marzo atajamos el problema configurando un límite de ranuras para algunos de los trabajos del proyecto. En naranja, tenemos los costes de BigQuery en esa modalidad. En azul seguimos teniendo el coste de los usos concretos y puntuales que quedaban fuera de esa limitación. Podemos ver cómo bajó drásticamente el gasto total. Y, con un límite adecuado a la carga real de trabajo, sin un impacto excesivo en los usuarios. Los tiempos de ejecución de las consultas y de carga de los cuadros de mando seguían siendo razonables.
En conclusión, no hay que tenerle miedo a los costes de usar BigQuery. Gracias a esta forma de controlar el uso de recursos, podemos alcanzar un equilibrio perfecto entre la potencia, escalabilidad y comodidad de esta herramienta y la posibilidad de ajustarnos a un presupuesto reduciendo enormemente los costes por el camino.
Para más información sobre modalidades, prestaciones, límites y costes, os recomendamos consultar la documentación oficial de Google al respecto. Y, por supuesto, podéis contar con Datarmony, partner oficial de Google, para ayudaros a sacarle todo el partido tanto a BigQuery en particular como a Google Cloud en general.