
Camila Larrosa
En un post anterior ya tratamos el tema de la optimización del clima laboral a través del análisis de redes. En ese artículo, decíamos que hoy en día los empleados no sólo buscan un salario competitivo, si no que además tienen en cuenta otros factores a la hora de valorar su vida laboral, y decidir si permanecer o no en una empresa. Dichos factores, según Forbes y por resumir, son:
- El reconocimiento
- La conciliación
- El trabajo en equipo
- El respeto por los horarios laborales
- La existencia de un plan de carrera
- Los retos
- Un equipo directivo referente
De todos ellos, el trabajo en equipo es quizá uno de los principales ingredientes de un clima laboral sano, y un clima laboral sano repercute en la productividad de forma positiva. En Datarmony usamos los datos para optimizar las relaciones y asegurar un entorno de trabajo en el que la gente esté a gusto.
Grupos, grupos y más grupos
Toda actividad humana genera grupos que comparten ciertas características. Entender lo que define a estos grupos permite tomar decisiones más adecuadas con respecto a ellos. El tipo de decisiones que pueden adoptarse depende de la naturaleza de los grupos y ésta, a su vez, depende de los datos que se han utilizado para detectarlos.

Por ejemplo, si los datos que tenemos están relacionados con los patrones de compra, los grupos que encontraremos estarán relacionados con distintos tipos de clientes o potenciales clientes según sus hábitos de consumo, a los que podremos lanzar acciones de comunicación diferenciadas. Este sería un claro ejemplo de aplicación de clusters en terreno del marketing.
Clusters según patrones de comunicación
Si, en cambio, analizamos los patrones de comunicación de las personas que conforman una empresa, encontraremos grupos de empleados que se comportan de forma similar a la hora de comunicarse con los demás.
En Datarmony, y como complemento al análisis de redes que realizamos de forma periódica, generamos clusters con los datos de interacción disponibles en los registros de uso de las cuentas corporativas de correo, Meet y Calendar, y en el programa de gestión de proyectos.
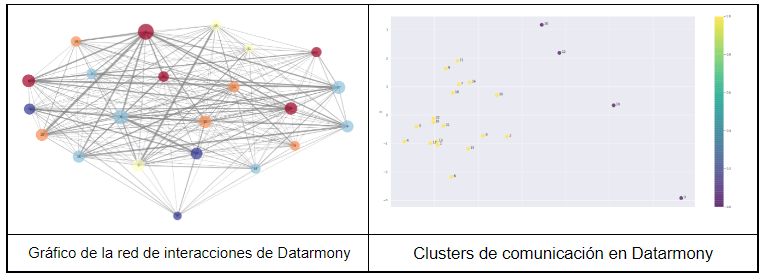
Ambos análisis (el de redes y el de clusters) son complementarios, porque muestran la misma realidad desde diferentes puntos de vista. No olvidemos que en ambos hemos utilizado los mismos datos.
Dos caras de una misma moneda
El primero nos da una idea de la fluidez de la comunicación y de la posición de las personas en la red. El segundo nos indica quiénes conforman los grupos, y quiénes se quedan fuera. Las dos caras de una misma moneda que permite saber, por un lado, quién está aislado y necesita ayuda, y por otro en qué grupo deberían estar las personas según su perfil.
Es importante destacar que una situación concreta no es ni buena ni mala a priori, y depende de los perfiles incluidos en el análisis. Hay gente que por su trabajo es normal hallarlos en el centro de la red, y formando parte de un cluster determinado. Otras personas, en cambio, encuentran su posición normal en la periferia, y quizá en un cluster menos compacto o directamente en ninguno.
Los que hay que mirar con lupa son aquellos casos cuya posición en la red o su clasificación dentro de los clusters no se corresponde con lo que cabría esperar según la naturaleza de su trabajo.
Los grupos no sólo dependen del tipo de datos incluidos en el modelo, también del algoritmo que se use para detectarlos, y de cómo se ajusta dicho algoritmo. El gráfico de clusters incluido anteriormente se ha hecho tras desarrollar un análisis de componentes principales (PCA), y aplicar el modelo de clusterización conocido como K-Means. En este caso concreto, el número de clusters predefinido ha sido establecido en 2 (seleccionado tras realizar un análisis de Silueta).
Inciso: ¿por qué PCA?
El análisis de componentes principales se usa a menudo para reducir el número de dimensiones con las que se trabaja para construir un modelo. Demasiadas dimensiones exigen muchos datos, y no garantizan buenos resultados. Por otra parte, la única manera de presentar un gráfico en dos dimensiones de los clusters es trabajar con las dos componentes principales (PCA-1 y PCA-2). Esto es lo que nos permite visualizar de forma sencilla los grupos encontrados. Recordemos que los seres humanos no podemos visualizar nada por encima de tres dimensiones. Y tres dimensiones en una pantalla de dos ya es complicado.
Volviendo al tema principal
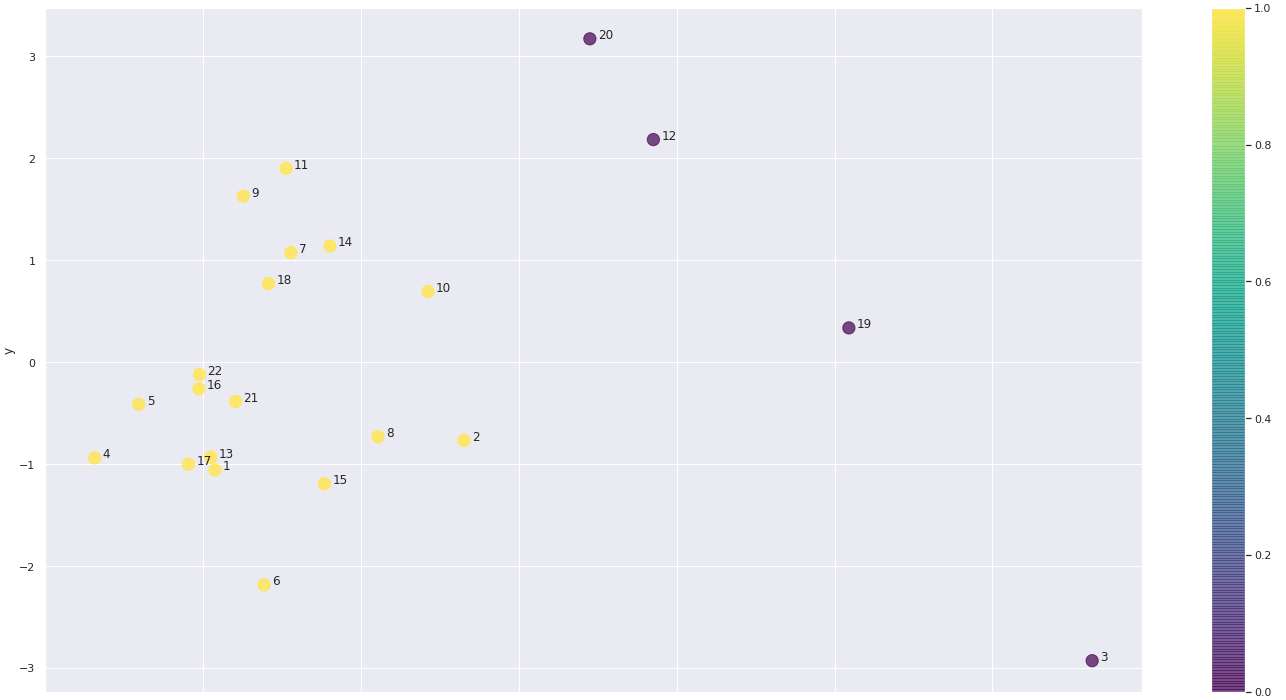
El resultado nos ha permitido detectar dos grupos. Los datos están anonimizados por razones de privacidad, pero quienes trabajamos en Datarmony podemos determinar a quién representa cada punto.
K-Means (con k = 2) genera dos clusters, amarillos y morados. Los amarillos son gente que está más en contacto entre sí y que trabaja en projectos (más de consultoría/producción). Los morados son en su mayoría gente de estructura (dirección, ventas, marketing y estrategia).
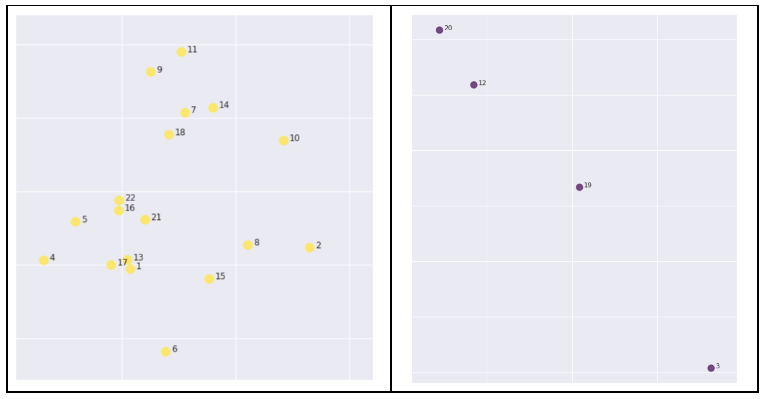
Los grupos están lejos de ser óptimos, aunque tienen cierta lógica (no olvidemos que estamos representando una realidad multidimensional en solo dos dimensiones). DBSCAN clustering (otro algoritmo de clusterización), por ejemplo, podría poner a los puntos morados y algún amarillo fuera de cualquier grupo.
Estas diferencias provienen de cómo funcionan los algoritmos. En K-Means todo punto debe pertenecer a un cluster (es un representante de lo que se conoce como Hard Clustering). En DBSCAN, en cambio, puede haber puntos que no pertenezcan a ningún cluster.
Siguiendo con K-Means, que en este caso concreto arroja los resultados más interpretables, y más acordes con la situación real (no olvidemos que el conocimiento de campo es esencial para interpretar correctamente los resultados), incluso dentro de los amarillos hay subgrupos definidos. Aunque la característica común es que se trata de comportamientos más relacionados con consultoría, producción y desarrollo de proyectos, también se ven otras cosas:
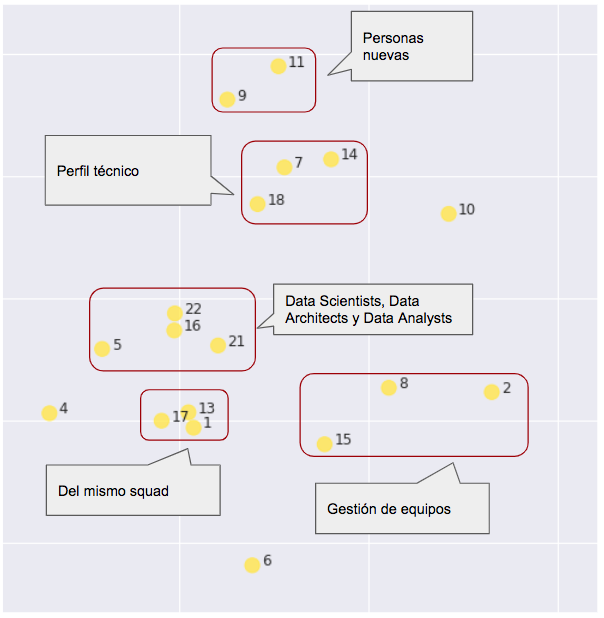
En cuanto a los morados:
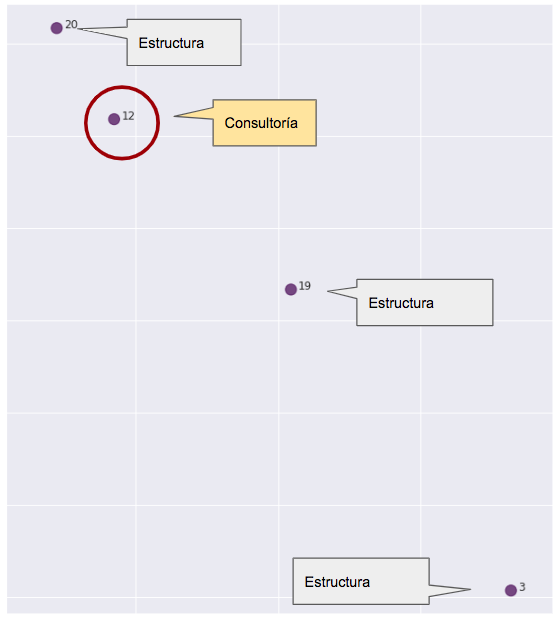
Los morados en realidad no son un grupo compacto. Su forma de operar es muy diversa, pero comparten una realidad incuestionable: la mayoría no es gente de producción. No son personas involucradas en el desarrollo de proyectos. K-Means, con todos sus defectos, e incluso con la pérdida de información asociada a una reducción dimensional, ha sido capaz de ver esto.
La justificación de todo el análisis
Pero aquí encontramos aquello que hace que todo este análisis valga la pena: el punto 12.
El punto 12 es un perfil de consultoría. La pregunta no es tanto ¿por qué está entre los morados?, sino más bien ¿por qué no está con los amarillos?
El análisis de redes no muestra esto, y el de clusters no dice nada sobre la calidad de la comunicaciones. De hecho, los puntos destacados en ambos gráficos ni siquiera representan a la misma persona, porque cuentan cosas distintas. Pero ambos juntos nos cuentan una historia completa, y nos enseñan facetas que por sí solos no pueden mostrar.
Con esta información, tanto managers como RRHH pueden investigar por qué los patrones de comunicación del punto 12 (no lo olvidemos, es una persona concreta) son tan distintos a los que se supone que debería tener según su puesto de trabajo. Puede que no haya ningún problema, puede que todo sea normal y que la persona esté operando de enlace entre ambos mundos. Pero también puede pasar que ese comportamiento se deba a problemas de comunicación que deban ser resueltos para el bien de todos.
Las diferencias
Durante todo el post hemos mencionado que los grupos de un mismo cluster comparten características similares pero, ¿qué hace que los amarillos y los morados sean diferentes?
Si comparamos la distribución de las variables con las que se ha construido el modelo, vemos que algunas separan a los grupos de forma muy clara. Aquí, por sencillez, hemos llamado a los amarillos como “Consultoría” y a los morados como “Dirección y Ventas”, aunque en la práctica esto sea una simplificación:
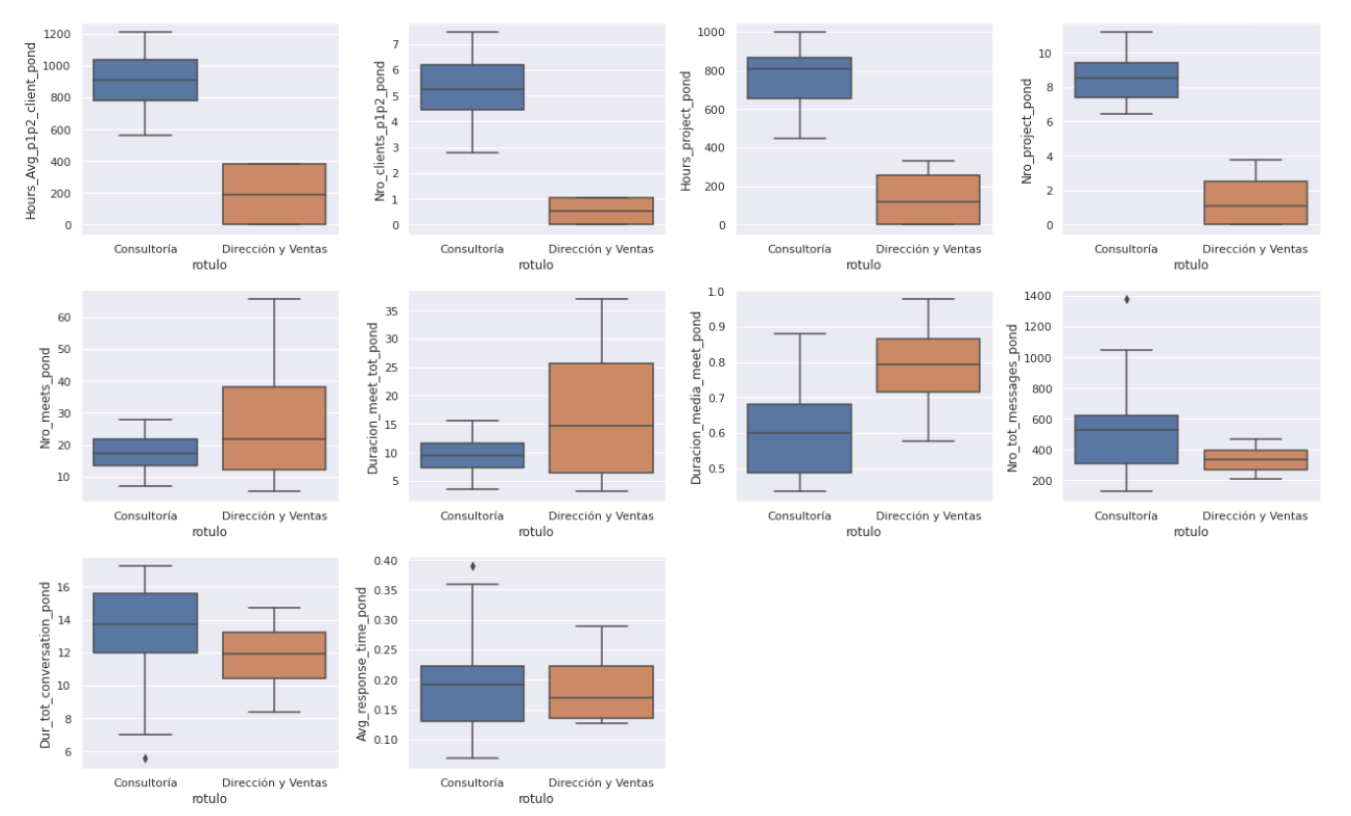
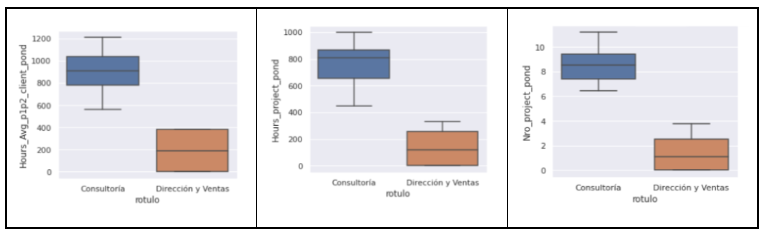
Por ejemplo, Consultoría dedica mucho más tiempo a tratar con los clientes que Dirección y Ventas, y ocupa mucho más tiempo en proyectos, como es lógico:
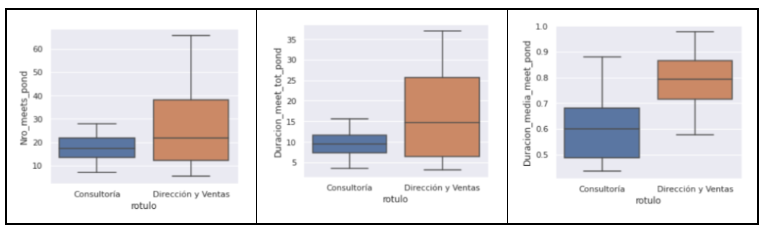
Dirección, por su parte tiende a reunirse más veces, durante más tiempo:
En otros aspectos como el número de mensajes, la duración total de las conversaciones entre personas, y el tiempo medio de respuesta, los datos no diferencian claramente a los grupos. En otras palabras, en estos aspectos ambos clusters son similares:
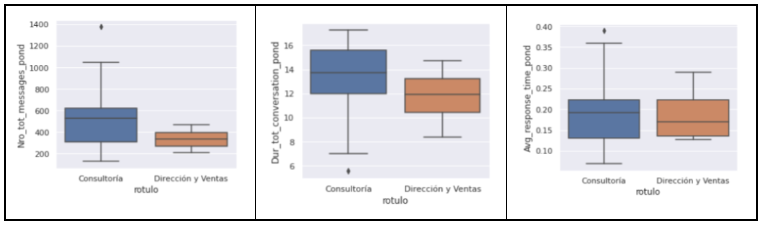
Con esta información podemos acercarnos al punto 12 y ver si necesita apoyo. A lo mejor está participando en reuniones muy largas, lo que podría afectar a su productividad. Quizá no está integrado de forma clara en producción, y está asumiendo tareas más de estructura. En el peor de los casos está aislado y no se le están dando tareas de producción, (entonces se vería en el diagrama de red ocupando una posición periférica).
De nuevo, es necesario decir que a priori la situación no tiene porqué ser negativa. La realidad se debe establecer con un análisis cualitativo. Lo importante es que gracias a los datos sabemos donde debemos poner el foco para optimizar la comunicación en la empresa.